Redis 与其他 key – value 缓存产品有以下三个特点:
性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,应为数据量不能大于硬件内存。在内存数据库方面的另一个优点是, 相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。 同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 2 32 – 1(4294967295, 每个集合可存储40多亿个成员)。
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
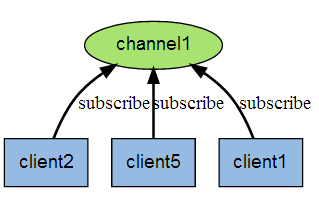
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
pubsub1
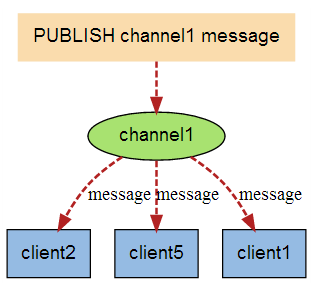
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
一个事务从开始到执行会经历以下三个阶段:
Redis 支持简单且易用的主从复制(master-slave replication)功能, 该功能可以让从服务器(slave server)成为主服务器(master server)的精确复制品。
无论是初次连接还是重新连接, 当建立一个从服务器时, 从服务器都将向主服务器发送一个 SYNC 命令。 接到 SYNC 命令的主服务器将开始执行 BGSAVE , 并在保存操作执行期间, 将所有新执行的写入命令都保存到一个缓冲区里面。
当 BGSAVE 执行完毕后, 主服务器将执行保存操作所得的 .rdb 文件发送给从服务器, 从服务器接收这个 .rdb 文件, 并将文件中的数据载入到内存中。
之后主服务器会以 Redis 命令协议的格式, 将写命令缓冲区中积累的所有内容都发送给从服务器。
你可以通过 telnet 命令来亲自验证这个同步过程: 首先连上一个正在处理命令请求的 Redis 服务器, 然后向它发送 SYNC 命令, 过一阵子, 你将看到 telnet 会话(session)接收到服务器发来的大段数据(.rdb 文件), 之后还会看到, 所有在服务器执行过的写命令, 都会重新发送到 telnet 会话来。
即使有多个从服务器同时向主服务器发送 SYNC , 主服务器也只需执行一次 BGSAVE 命令, 就可以处理所有这些从服务器的同步请求。
从服务器可以在主从服务器之间的连接断开时进行自动重连, 在 Redis 2.8 版本之前, 断线之后重连的从服务器总要执行一次完整重同步(full resynchronization)操作, 但是从 Redis 2.8 版本开始, 从服务器可以根据主服务器的情况来选择执行完整重同步还是部分重同步(partial resynchronization)。
从 Redis 2.8 开始, 在网络连接短暂性失效之后, 主从服务器可以尝试继续执行原有的复制进程(process), 而不一定要执行完整重同步操作。
这个特性需要主服务器为被发送的复制流创建一个内存缓冲区(in-memory backlog), 并且主服务器和所有从服务器之间都记录一个复制偏移量(replication offset)和一个主服务器 ID (master run id), 当出现网络连接断开时, 从服务器会重新连接, 并且向主服务器请求继续执行原来的复制进程:
如果从服务器记录的主服务器 ID 和当前要连接的主服务器的 ID 相同, 并且从服务器记录的偏移量所指定的数据仍然保存在主服务器的复制流缓冲区里面, 那么主服务器会向从服务器发送断线时缺失的那部分数据, 然后复制工作可以继续执行。
否则的话, 从服务器就要执行完整重同步操作。
Redis 2.8 的这个部分重同步特性会用到一个新增的 PSYNC 内部命令, 而 Redis 2.8 以前的旧版本只有 SYNC 命令, 不过, 只要从服务器是 Redis 2.8 或以上的版本, 它就会根据主服务器的版本来决定到底是使用 PSYNC 还是 SYNC :
如果主服务器是 Redis 2.8 或以上版本,那么从服务器使用 PSYNC 命令来进行同步。
如果主服务器是 Redis 2.8 之前的版本,那么从服务器使用 SYNC 命令来进行同步。
从 Redis 2.6 开始, 从服务器支持只读模式, 并且该模式为从服务器的默认模式。 只读模式由 redis.conf 文件中的 slave-read-only 选项控制, 也可以通过 CONFIG SET 命令来开启或关闭这个模式。
只读从服务器会拒绝执行任何写命令, 所以不会出现因为操作失误而将数据不小心写入到了从服务器的情况。
即使从服务器是只读的, DEBUG 和 CONFIG 等管理式命令仍然是可以使用的, 所以我们还是不应该将服务器暴露给互联网或者任何不可信网络。 不过, 使用 redis.conf 中的命令改名选项, 我们可以通过禁止执行某些命令来提升只读从服务器的安全性。
你可能会感到好奇, 既然从服务器上的写数据会被重同步数据覆盖, 也可能在从服务器重启时丢失, 那么为什么要让一个从服务器变得可写呢?
原因是, 一些不重要的临时数据, 仍然是可以保存在从服务器上面的。 比如说, 客户端可以在从服务器上保存主服务器的可达性(reachability)信息, 从而实现故障转移(failover)策略。
从 Redis 2.8 开始, 为了保证数据的安全性, 可以通过配置, 让主服务器只在有至少 N 个当前已连接从服务器的情况下, 才执行写命令。 不过, 因为 Redis 使用异步复制, 所以主服务器发送的写数据并不一定会被从服务器接收到, 因此, 数据丢失的可能性仍然是存在的。
以下是这个特性的运作原理:
从服务器以每秒一次的频率 PING 主服务器一次, 并报告复制流的处理情况。
主服务器会记录各个从服务器最后一次向它发送 PING 的时间。
用户可以通过配置, 指定网络延迟的最大值 , 以及执行写操作所需的至少从服务器数量如果至少有 min-slaves-to-write 个从服务器, 并且这些服务器的延迟值都少于 min-slaves-max-lag 秒, 那么主服务器就会执行客户端请求的写操作。
你可以将这个特性看作 CAP 理论中的 C 的条件放宽版本: 尽管不能保证写操作的持久性, 但起码丢失数据的窗口会被严格限制在指定的秒数中。
另一方面, 如果条件达不到min-slaves-to-write 和 min-slaves-max-lag 所指定的条件, 那么写操作就不会被执行, 主服务器会向请求执行写操作的客户端返回一个错误。
以下是这个特性的两个选项和它们所需的参数:
详细的信息可以参考 Redis 源码中附带的 redis.conf 示例文件。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
