所以就在你买了你的第一个域名的时候,Java来了,并且在一个句子之后随便说一句“dot com”是很酷的。而Java具有语言内置的多线程(特别是在创建时),这一点非常棒。
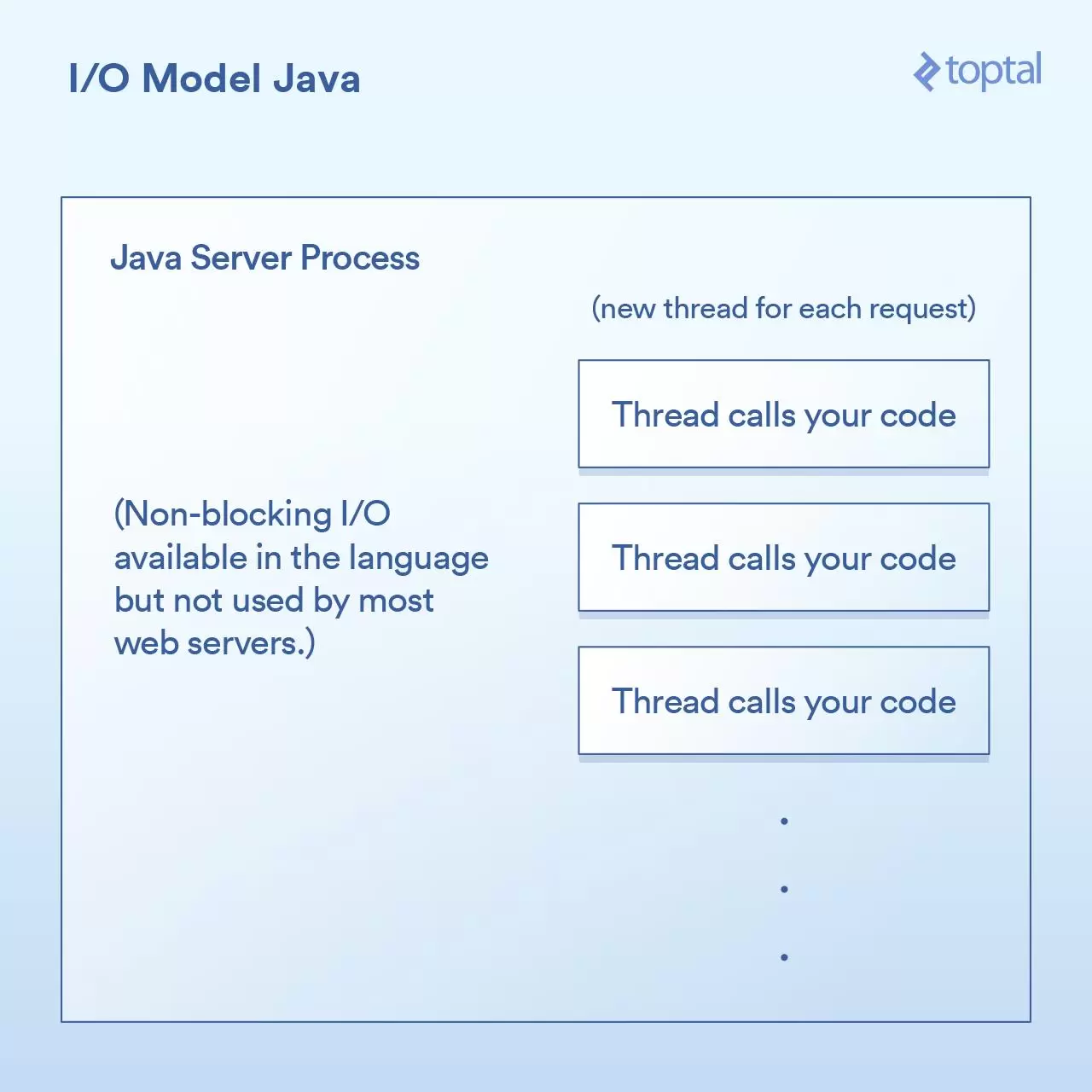
大多数Java网站服务器通过为每个进来的请求启动一个新的执行线程,然后在该线程中最终调用作为应用程序开发人员的你所编写的函数。
在Java的Servlet中执行I/O操作,往往看起来像是这样:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// 阻塞的文件I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// 阻塞的网络I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// 更多阻塞的网络I/O
out.println("...");
}由于我们上面的doGet方法对应于一个请求并且在自己的线程中运行,而不是每次请求都对应需要有自己专属内存的单独进程,所以我们会有一个单独的线程。
这样会有一些不错的优点,例如可以在线程之间共享状态、共享缓存的数据等,因为它们可以相互访问各自的内存,但是它如何与调度进行交互的影响,仍然与前面PHP例子中所做的内容几乎一模一样。
每个请求都会产生一个新的线程,而在这个线程中的各种I/O操作会一直阻塞,直到这个请求被完全处理为止。
为了最小化创建和销毁它们的成本,线程会被汇集在一起,但是依然,有成千上万个连接就意味着成千上万个线程,这对于调度器是不利的。
一个重要的里程碑是,在Java 1.4 版本(和再次显著升级的1.7 版本)中,获得了执行非阻塞I/O调用的能力。大多数应用程序,网站和其他程序,并没有使用它,但至少它是可获得的。一些Java网站服务器尝试以各种方式利用这一点; 然而,绝大多数已经部署的Java应用程序仍然如上所述那样工作。
 Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
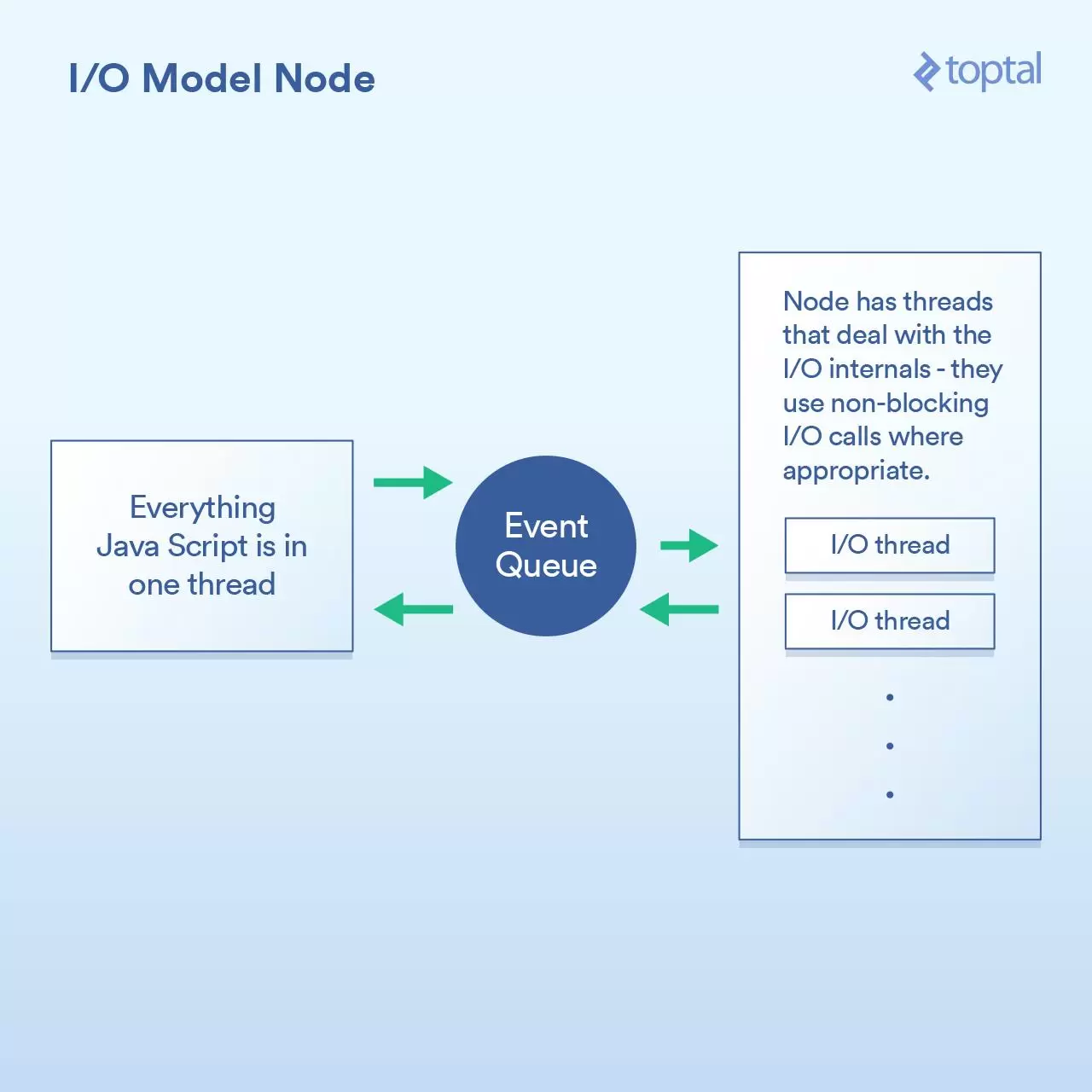
当谈到更好的I/O时,Node.js无疑是新宠。任何曾经对Node有过最简单了解的人都被告知它是“非阻塞”的,并且它能有效地处理I/O。在一般意义上,这是正确的。但魔鬼藏在细节中,当谈及性能时这个巫术的实现方式至关重要。
本质上,Node实现的范式不是基本上说“在这里编写代码来处理请求”,而是转变成“在这里写代码开始处理请求”。每次你都需要做一些涉及I/O的事情,发出请求或者提供一个当完成时Node会调用的回调函数。
在求中进行I/O操作的典型Node代码,如下所示:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});可以看到,这里有两个回调函数。第一个会在请求开始时被调用,而第二个会在文件数据可用时被调用。
这样做的基本上给了Node一个在这些回调函数之间有效地处理I/O的机会。一个更加相关的场景是在Node中进行数据库调用,但我不想再列出这个烦人的例子,因为它是完全一样的原则:启动数据库调用,并提供一个回调函数给Node,它使用非阻塞调用单独执行I/O操作,然后在你所要求的数据可用时调用回调函数。这种I/O调用队列,让Node来处理,然后获取回调函数的机制称为“事件循环”。它工作得非常好。
然而,这个模型中有一道关卡。在幕后,究其原因,更多是如何实现JavaScript V8 引擎(Chrome的JS引擎,用于Node)1,而不是其他任何事情。
你所编写的JS代码全部都运行在一个线程中。思考一下。这意味着当使用有效的非阻塞技术执行I/O时,正在进行CPU绑定操作的JS可以在运行在单线程中,每个代码块阻塞下一个。
一个常见的例子是循环数据库记录,在输出到客户端前以某种方式处理它们。以下是一个例子,演示了它如何工作:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// 对每一行纪录进行处理
}
response.end(...); // 输出结果
})
};虽然Node确实可以有效地处理I/O,但上面的例子中的for循环使用的是在你主线程中的CPU周期。这意味着,如果你有10,000个连接,该循环有可能会让你整个应用程序慢如蜗牛,具体取决于每次循环需要多长时间。每个请求必须分享在主线程中的一段时间,一次一个。
这个整体概念的前提是I/O操作是最慢的部分,因此最重要是有效地处理这些操作,即使意味着串行进行其他处理。这在某些情况下是正确的,但不是全都正确。
另一点是,虽然这只是一个意见,但是写一堆嵌套的回调可能会令人相当讨厌,有些人认为它使得代码明显无章可循。在Node代码的深处,看到嵌套四层、嵌套五层、甚至更多层级的嵌套并不罕见。
我们再次回到了权衡。如果你主要的性能问题在于I/O,那么Node模型能很好地工作。然而,它的阿喀琉斯之踵(译者注:来自希腊神话,表示致命的弱点)是如果不小心的话,你可能会在某个函数里处理HTTP请求并放置CPU密集型代码,最后使得每个连接慢得如蜗牛。
在进入Go这一章节之前,我应该披露我是一名Go粉丝。我已经在许多项目中使用Go,是其生产力优势的公开支持者,并且在使用时我在工作中看到了他们。
也就是说,我们来看看它是如何处理I/O的。Go语言的一个关键特性是它包含自己的调度器。并不是每个线程的执行对应于一个单一的OS线程,Go采用的是“goroutines”这一概念。Go运行时可以将一个goroutine分配给一个OS线程并使其执行,或者把它挂起而不与OS线程关联,这取决于goroutine做的是什么。来自Go的HTTP服务器的每个请求都在单独的Goroutine中处理。
此调度器工作的示意图,如下所示:

这是通过在Go运行时的各个点来实现的,通过将请求写入/读取/连接/等实现I/O调用,让当前的goroutine进入睡眠状态,当可采取进一步行动时用信息把goroutine重新唤醒。
实际上,除了回调机制内置到I/O调用的实现中并自动与调度器交互外,Go运行时做的事情与Node做的事情并没有太多不同。它也不受必须把所有的处理程序代码都运行在同一个线程中这一限制,Go将会根据其调度器的逻辑自动将Goroutine映射到其认为合适的OS线程上。最后代码类似这样:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 这里底层的网络调用是非阻塞的
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// 处理rows
// 每个请求在它自己的goroutine中
}
w.Write(...) // 输出响应结果,也是非阻塞的
}正如你在上面见到的,我们的基本代码结构像是更简单的方式,并且在背后实现了非阻塞I/O。
在大多数情况下,这最终是“两个世界中最好的”。非阻塞I/O用于全部重要的事情,但是你的代码看起来像是阻塞,因此往往更容易理解和维护。Go调度器和OS调度器之间的交互处理了剩下的部分。这不是完整的魔法,如果你建立的是一个大型的系统,那么花更多的时间去理解它工作原理的更多细节是值得的; 但与此同时,“开箱即用”的环境可以很好地工作和很好地进行扩展。
Go可能有它的缺点,但一般来说,它处理I/O的方式不在其中。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
