SQL是一种关系代数,在进行关系代数等价转换时,我们利用Metadata获得更多的上下文和数据信息,而从获得更优的执行计划。
为了进一步介绍Metadata如何让优化器更加“Smart”,接下来会先介绍几种使用Metadata的场景。
SELECT trade_date, count(trade_id) cnt_of_trades FROM trades GROUP BY trade_date;这个语句是想要以交易日为单元,计算交易日内的交易笔数。而语句的执行效率(时间)依赖于数据的分布情况。
假设收到的trades数据集合如图1:
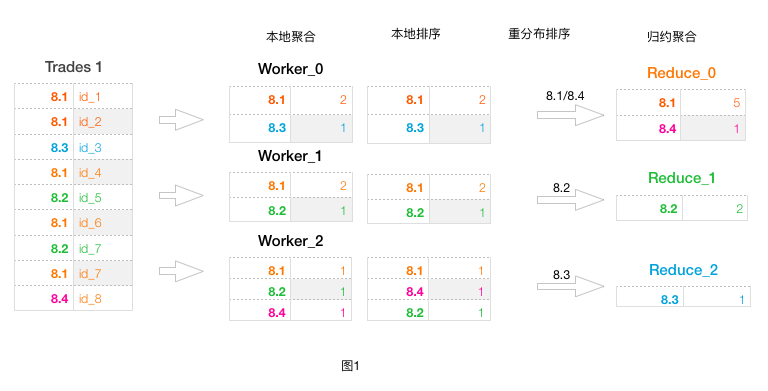 为了计算这个聚合操作,在分布式数据处理系统中,会把trades数据分成多份。假设分成3份,由3个Worker进行初步处理。处理的流程如下:
为了计算这个聚合操作,在分布式数据处理系统中,会把trades数据分成多份。假设分成3份,由3个Worker进行初步处理。处理的流程如下:
a. 本地聚合,将本地看到的数据进行trade_date聚合计算 b. 本地排序,将同个分布桶内的数据根据trade_date进行排序 c. 重分布排序,是Reduce之前的处理。它将多个前置Worker产生的多个分布桶数据进行归并排序 d. 归约聚合,再将最终的数据进行全局的聚合
如上是一般情况下Trades数据时的操作流程。本地聚合起到了减少数据量的功能,对于Worker_0输入有3条记录,但向后输出只需要2条记录。本地排序和重分布排序是将数据排序,使得归约聚合操作每次只针对一个group进行。 接下来,咱们看一些特殊的数据,如下图2:
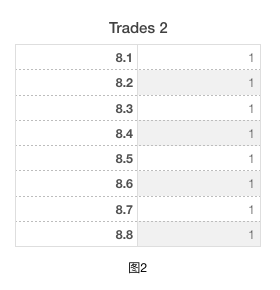
图2中可以看到每个trade_date只有一笔交易。从刚才通用的处理流程中可以看到: a. 本地聚合没起到任何数据减少作用,因为每个Worker收到的交易列表里没有重复trade_date b. 两个排序操作进行数据归并处理也是无用功,因为每笔交易都是属于一个group
对于此种场景,我们就可以把“本地聚合”、“本地排序”和“重分布排序”阶段去掉,直接跳至归约聚合即可以。 这些数据特征可以通过何种方式发现呢?这就是本篇想要引出的主题——Metadata(元数据)
什么是Metadata?概括地说,它是数据特征的描述。SQL描述了数据的处理逻辑,从原始数据作为初始数据集合,经过关系代数的基本运算而得到最终的结果数据集合。而Metadata信息的最初始来源是原始数据自身的特征,同时包含了中间过程的数据推导计算。
借由前面的例子,将SQL转换成关系代数的运算符描述,如图:
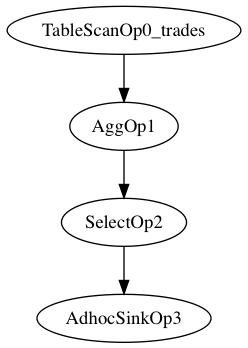
TableScanOp0_trades表示从表trades上读取原始数据 AggOp1表示将原始数据根据trade_date进行聚合操作 SelectOp2表示将聚合的结果展现出来 AdhocSinkOp3表示在标准输出中显示结果
前面场景所描述的“本地聚合”、“本地排序”、“重分布排序”和“归约聚合”就是AggOp1的物理执行操作描述。
优化器拿到此逻辑操作DAG图后就开始着手将它转换成物理操作DAG图(TableScanOp0_trades、SelectOp2和AdhocSinkOp3在此处不着重讲述)。优化器会生成代数等价的两种选择,如下图所示:
两种执行计划如何选择,优化器依靠的是cost(代价)计算。plan的输入数据量是一致的(假设为rc0)。
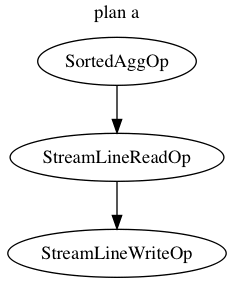
对于plan a,它对输入数据没有任何处理,所以网络分发和排序的数据量为rc0,而后对rc0的数据进行reduce端的聚合操作。
对于plan b,它对输入数据进行了本地聚合(HashAgg),若本地存在重复Key的数据,则网络分发和排序的数据量则会压缩成rc1(假设压缩后的数据量)。
当HashAgg计算结果的“压缩”率越高(即rc1越小),则网络分发和排序的数据量就越小。如Trade1和Trade2两种数据特征。Trade1情况下,利用HashAggOp就可以减少网络分发和排序的数据量。而Trade2因为数据不存在重复性(交易单中每天只有一单交易),所以Plan b的HashAggOp没有减少数据量,如此StreamLineWriteOp的输入数据跟Plan a的StreamLineWriteOp是一样的。
从整体上看,Plan b增加了HashAggOp的计算的浪费,所以Plan a的代价比较小,如此在Trade 2情况下就会选择Plan a。
从上面的分析可以看出,关键点在于HashAggOp操作产生的数据特征。HashAggOp是进行本地聚合,当输出减少的数据量所获得的利润空间大于HashAggOp自身的计算代价时,Plan b就会被推举。而如何判断输出数据量呢?
优化器利用的是一种Metadata:Number of Distinct Value (NDV)。
对于Trade例子,HashAggOp操作想要知道它的输出数据量,就需要知道它的输入操作符中对于相关列的NDV值,即Output(HashAggOp) = NDV(inputOp)。NDV的计算依赖于三个信息:操作符类型、引用列和当前的过滤条件。
inputOp可能是各种各样的操作符,而不同的操作符,计算的NDV的算法有所不同:
目前优化器针对于原始数据NDV计算有两种方式:一种是Analyze语句手动触发;另一种是在数据生成时并行收集。这两种方法收集的统计项除了NDV外还有其它一些常用的信息,包含:
a. avgColLen:平均行的长度 b. maxColLen:最大行的长度 c. minValue:最小值 d. maxValue:最大值 e. estimateCountDistinct:即NDV,不同值个数 f. numNulls:null个数 g. numFalses:false个数(boolean有效) h. numTrues:true个数(boolean有效) i. topK:前k个值的占比 这些统计信息被用来Metadata的原始数据,最终体现在Metadata的演算中。
Metadata是优化器的核心模块,它为优化系统提供更多的数据信息以获得更优的执行计划。除了MdDistinctRowCount(NDV)外,我们还提供了MdPredicates(获得前置谓词)、MdRowCount(获得数据行数)、MdSize(获得数据列长度)等等。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
