弹性分布式数据集(RDD)是Spark的基本数据结构。它是对象的不可变的分布式集合。在RDD中每个数据集被划分成逻辑分区,这可能是在群集中的不同节点上计算的。RDDS可以包含任何类型,如:Python,Java,或者Scala的对象,包括用户定义的类。
形式上,一个RDD是只读的,分割的记录集。RDDs 可以数据创建通过确定运算在稳定的存储或其他RDDs 。RDD是可以并行进行操作元素的容错集合。
有两种方法来创建RDDs − 并行现有集合中的驱动器程序,或在外部存储系统引用的数据集,如共享文件系统,HDFS,HBase,或任何数据源提供Hadoop的输入格式。
Spark利用RDD概念,以实现更快,更高效的MapReduce作业。让我们先讨论MapReduce如何操作,为什么不那么有效。
MapReduce被广泛用于处理和生成大型数据集并行,分布在集群上的算法。它允许用户编写并行计算,使用一组高层次的操作符,而不必担心工作分配和容错能力。
遗憾的是,目前大多数的框架,只有这样,才能重新使用计算(前 - 两个MapReduce工作之间)之间的数据是将其写入到一个稳定的外部存储系统(前- HDFS)。虽然这个框架提供了大量的抽象访问群集的计算资源,但用户还是想要更多。
这两个迭代和互动应用需要跨并行作业更快速的数据共享。数据共享MapReduce是缓慢的,因为复制,序列化和磁盘IO。在存储系统中,大多数的 Hadoop 应用,它们花费的时间的90%以上是用于做HDFS读 - 写操作。
重复使用多个计算中间结果在多级的应用程序。下图说明了如何在当前的框架工作,同时做迭代操作上的MapReduce。这会带来大量的开销,由于数据复制,磁盘I / O,和系列化,使系统变慢。
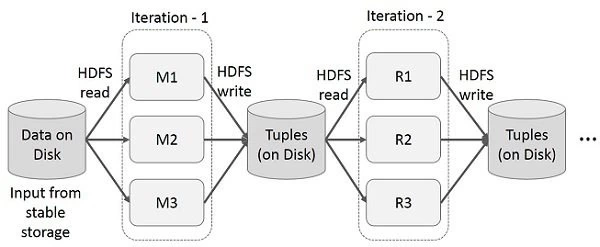
用户运行即席查询,数据的相同子集。每个查询会做稳定存储,它可以主宰应用程序执行的磁盘I/O时间。
下图说明了如何在当前的框架工作同时做交互查询在MapReduce上。
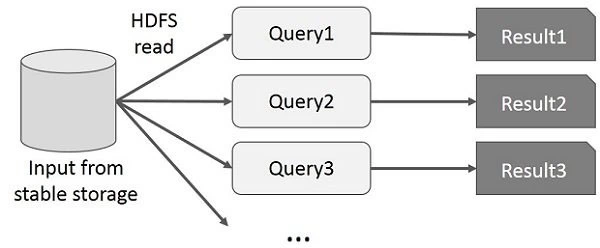
数据共享MapReduce是缓慢的,因为复制,序列化和磁盘IO。大多数的Hadoop应用,他们花费的时间的90%以上是做HDFS读 - 写操作。
认识到这个问题,研究人员专门开发了一种称为Apache Spark框架。spark的核心思想是弹性分布式数据集(RDD); 它支持在内存中处理运算。这意味着,它存储存储器的状态作为两端作业的对象以及对象在那些作业之间是可共享的。在存储器数据共享比网络和磁盘快10到100倍。
现在让我们理解迭代和交互式操作是如何发生在Spark RDD中。
下面给出的图显示Spark RDD迭代操作。它将存储中间结果放在分布式存储器,而不是稳定的存储(磁盘)和使系统更快。
注 − 如果分布式存储器(RAM)足以存储中间结果(该作业状态),那么它将存储这些结果的磁盘上。
该图显示Spark RDD的交互式操作。如果不同查询在同一组数据的反复运行,该特定数据可被保存在内存中以获得更好的执行时间。
默认情况下,每个变换RDD可以在每次运行在其上的动作时间重新计算。但是,也可能会持续一个RDD在内存中,在这种情况下,Spark将保持周围群集上以获得非常快速访问,在你查询它的下一次用上。另外也用于在磁盘上持续RDDS支持,或在多个节点间复制。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
