实施外部工具可以定期通过暴露终端访问应用程序中的功能检查。这个模式可以帮助验证的应用和服务被正确执行。
它是很好的做法,并且通常是一个业务需求,并监控web应用程序,和中间层和共享服务,以确保它们是可用的,并执行正确的。然而,它更难以监测在云中运行比它要监控本地服务的服务。举例来说,你不必完全控制主机环境,而服务通常依赖于平台,供应商和其他公司提供其他服务。
也有一些影响云托管的应用,如网络延迟,性能和下面的计算和存储系统的可用性,以及它们之间的网络带宽的因素很多。由于任何这些因素的服务可能完全或部分失败。因此,您必须定期验证服务正在执行正确,以确保可用性,这可能是您的服务级别协议(SLA)的一部分所要求的水平。
通过将请求发送到应用程序的端点实施健康监测。该应用程序应该执行必要的检查,并返回其状态的指示。
一种保健监测检查通常结合了两个因素:检查(如果有的话)的应用程序或服务响应于所述请求发送到健康验证端点执行,并且结果由工具或框架正在执行健康检查验证的分析。的响应代码表示的应用程序的状态和任选的任何组件或服务,它使用。的延迟或响应时间检查由监测工具或框架进行。图1示出了该模式的执行的概述。
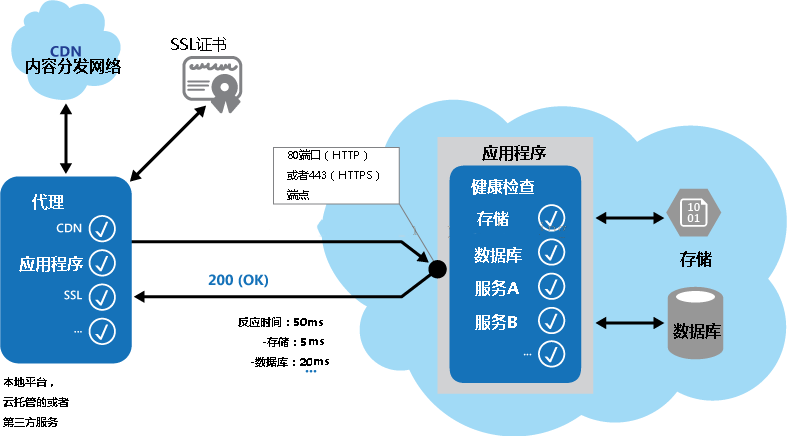
图1 - 模式概述
附加的检查,可能如下进行:在该应用程序的运行状况监视代码包括:
几个现有的服务和工具可用于监视 web 应用程序通过提交一个请求到一组可配置的端点,并评价针对一组可配置的规则的结果。它相对容易地创建一个服务端点,其唯一的目的是要在系统上执行一些功能测试。
这可以通过监控工具来执行典型的检查包括:
它也是有用的,在可能情况下,以内部部署和托管的位置运行,从这些不同的检查,以测量和来自不同地方比较的响应时间。理想情况下,你应该监视那些贴近客户,以得到每个位置的性能进行精确的视图位置的应用程序。除了提供一个更为坚固的检查机制,其结果可能会影响部署位置的选择的应用程序,以及是否在一个以上的数据中心部署。
试验还应该对所有客户使用,以确保应用程序正常工作的所有顾客的服务实例运行。例如,如果客户的存储空间分布在多个存储账户,在监测过程中,必须检查所有的这些。
在决定如何实现这个模式时,请考虑以下几点:
确保应用程序不会正确地当目标资源是发现和处理仅返回200状态码。在某些情况下,使用母版页来承载目标网页的时候,例如,服务器可能会返回一个 200 OK 状态码,而不是一个 404 未找到的代码,即使没有找到目标内容页面。
DoS 攻击是可能对一个单独的端点,它执行基本功能测试,而不会影响应用程序的动作的影响较小。理想情况下,应避免使用测试可能暴露敏感信息。如果你必须返回,可能是对攻击者有用的信息,考虑如何将保护端点免受未经授权的访问数据。在这种情况下,仅仅依靠默默无闻是不够的。还应该考虑使用 HTTPS 连接和加密的任何敏感数据,尽管这会增加服务器上的负载。
public ActionResult CoreServices()
{
try
{
// Run a simple check to ensure the database is available.
DataStore.Instance.CoreHealthCheck();
// Run a simple check on our external service.
MyExternalService.Instance.CoreHealthCheck();
}
catch (Exception ex)
{
Trace.TraceError("Exception in basic health check: {0}", ex.Message);
// This can optionally return different status codes based on the exception.
// Optionally it could return more details about the exception.
// The additional information could be used by administrators who access the
// endpoint with a browser, or using a ping utility that can display the
// additional information.
return new HttpStatusCodeResult((int)HttpStatusCode.InternalServerError);
}
return new HttpStatusCodeResult((int)HttpStatusCode.OK);
}
还要确保监控系统进行自身检查,如自检和内置的测试,以避免它在发出假阳性结果。
这种模式非常适合于:
下面的代码示例,从 HealthCheckController 类的 HealthEndpointMonitoring.Web 项目采取包括可以下载本指南的样品,演示露出一个端点进行一系列健康检查。
该 CoreServices 方法,如下所示,执行在应用程序中使用的服务的一系列检查。如果所有的测试中没有错误执行,该方法返回一个 200(OK)状态码。如果有任何的测试引发了异常,该方法返回一个 500(内部错误)状态码。当发生错误时的方法,可任选地返回附加信息,如果该监控工具或框架能够利用它。
该 ObscurePath 方法显示了如何读取应用程序配置的路径,并用它作为测试端点。这个例子也说明了如何接受一个 ID 作为参数,并用它来检查有效的请求。
public ActionResult ObscurePath(string id)
{
// The id could be used as a simple way to obscure or hide the endpoint.
// The id to match could be retrieved from configuration and, if matched,
// perform a specific set of tests and return the result. It not matched it
// could return a 404 Not Found status.
// The obscure path can be set through configuration in order to hide the endpoint.
var hiddenPathKey = CloudConfigurationManager.GetSetting("Test.ObscurePath");
// If the value passed does not match that in configuration, return 403 "Not Found".
if (!string.Equals(id, hiddenPathKey))
{
return new HttpStatusCodeResult((int)HttpStatusCode.NotFound);
}
// Else continue and run the tests...
// Return results from the core services test.
return this.CoreServices();
}
该 TestResponseFromConfig 方法显示了如何可以公开执行一个指定的配置设定值检查的端点。
public ActionResult TestResponseFromConfig()
{
// Health check that returns a response code set in configuration for testing.
var returnStatusCodeSetting = CloudConfigurationManager.GetSetting(
"Test.ReturnStatusCode");
int returnStatusCode;
if (!int.TryParse(returnStatusCodeSetting, out returnStatusCode))
{
returnStatusCode = (int)HttpStatusCode.OK;
}
return new HttpStatusCodeResult(returnStatusCode);
}
监控端点在 Azure 中托管的应用程序
在Azure应用程序监控终端的一些选项包括:
注意: 尽管 Azure 提供一个合理的全面的监控选项,您可以决定使用额外的服务和工具,以提供额外的信息。
Azure 管理服务提供了各地的警报规则建立了一个全面的内置监控机制。管理服务网页中的 Azure 管理门户 Alerts 部分,可以配置高达每认购10警报规则为您服务。这些规则指定一条件和用于服务诸如 CPU 负载的阈值,或每秒请求或错误的数量,并且该服务可以自动发送电子邮件通知给你在每个规则定义的地址。
您可以监视具体费用取决于您选择适合您的应用程序的托管机制的条件下(如网站,云服务,虚拟机,或移动服务),但所有这些,包括创建使用网络端点警报规则的能力您在为您服务的设置指定。此端点应该及时地作出反应,以使警报系统可以检测到该应用程序是否正常运行。
注意: 有关创建监视警报的详细信息,请参阅 MSDN 上的管理服务。
如果你的主机在 Azure 云服务网络和工作角色或虚拟机应用程序时,您可以采取的内置服务在Azure中所谓的流量管理器中的一个优势。流量管理器是一个路由和负载平衡服务,可以将请求分发到您的云服务托管的应用程序基于一系列的规则和设置的具体实例。
除了请求路由,流量管理坪的 URL,端口和相对你定期指定的路径来确定其规则中定义的应用程序的实例是活动的,并响应请求。如果它检测到一个状态代码 200(OK)它标志着应用程序可用,其他状态的代码会导致流量管理器来标记应用程序离线。您可以查看流量管理器控制台的状态和配置规则来重新路由请求被响应的应用程序的其他实例。
但是,请记住,流量管理器将只等待10秒钟,以接收来自监控URL的响应。因此,你应该确保你的健康验证码这个时间范围内执行,允许网络延迟从流量管理器往返于您的应用程序,然后再返回。
注意: 有关使用 Windows 流量管理器来监视你的应用程序的更多信息,请参阅 MSDN 上微软 Azure Traffic Manager 的。流量管理器在多个数据中心部署指南进行了讨论。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3
