SQ 由 3 个守护进程组成:
nsqd 是接收、队列和传送消息到客户端的守护进程。
nsqlookupd 是管理的拓扑信息,并提供了最终一致发现服务的守护进程。
在 NSQ 数据流建模为一个消息流和消费者的树。一个话题(topic)是一个独特的数据流。一个 通道(channel) 是消费者订阅了某个 话题 的逻辑分组。
单个 nsqd 可以有很多的话题,每个话题可以有多通道。一个通道接收到一个话题中所有消息的副本,启用组播方式的传输,使消息同时在每个通道的所有订阅用户间分发,从而实现负载平衡。
这些原语组成一个强大的框架,用于表示各种简单和复杂的拓扑结构。
话题和通道
话题(topic)和通道(channel),NSQ 的核心基础,最能说明如何把 Go 语言的特点无缝地转化为系统设计。
Go 语言中的通道(channel)(为消除歧义以下简称为“go-chan”)是实现队列一种自然的方式,因此一个 NSQ 话题(topic)/通道(channel),其核心,只是一个缓冲的 go-chan Message指针。缓冲区的大小等于 --mem-queue-size的配置参数。
在懂了读数据后,发布消息到一个话题(topic)的行为涉及到:
话题(topic) 时的读-锁;
从一个话题中的通道获取消息不能依赖于经典的 go-chan 语义,因为多个 goroutines 在一个 go-chan 上接收消息将会分发消息,而最终要的结果是复制每个消息到每一个通道(goroutine)。
替代的是,每个话题维护着 3 个主要的 goroutines。第一个被称为 router,它负责用来从 incoming go-chan 读取最近发布的消息,并把消息保存到队列中(内存或硬盘)。
第二个,称为 messagePump,是负责复制和推送消息到如上所述的通道。
第三个是负责 DiskQueue IO 和将在后面讨论。
通道是一个有点复杂,但共享着 go-chan 单一输入和输出(抽象出来的事实是,在内部,消息可能会在内存或磁盘上):
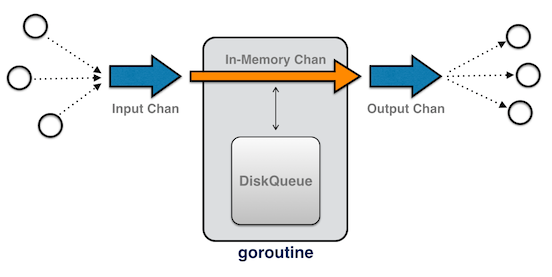
此外,每个通道的维护负责 2 个时间排序优先级队列,用来实现传输中(in-flight)消息超时(第 2 个随行 goroutines 用于监视它们)。
并行化的提高是通过每个数据结构管理一个通道,而不是依靠 Go 运行时的全局定时器调度。
注意:在内部,Go 运行时使用一个单一优先级队列和的 goroutine 来管理定时器。这支持(但不局限于)的整个 timepackage。它通常避免了需要一个用户空间的时间顺序的优先级队列,但要意识到这是一个很重要的一个有着单一锁的数据结构,有可能影响GOMAXPROCS > 1 的表现。
NSQ 的设计目标之一就是要限定保持在内存中的消息数。它通过 DiskQueue 透明地将溢出的消息写入到磁盘上(对于一个话题或通道而言,DiskQueue 拥有的第三个主要的 goroutine)。
由于内存队列只是一个 go-chan,把消息放到内存中显得不重要,如果可能的话,则退回到磁盘:
for msg := range c.incomingMsgChan {
select {
case c.memoryMsgChan <- msg:
default:
err := WriteMessageToBackend(&msgBuf, msg, c.backend)
if err != nil {
// ... handle errors ...
}
}
}
说到 Go select 语句的优势在于用在短短的几行代码实现这个功能:default 语句只在 memoryMsgChan 已满的情况下执行。
NSQ 还具有的临时通道的概念。临时的通道将丢弃溢出的消息(而不是写入到磁盘),在没有客户端订阅时消失。这是一个完美的 Go’s Interface 案例。话题和通道有一个结构成员声明为一个 Backend interface,而不是一个具体的类型。正常的话题和通道使用 DiskQueue,而临时通道连接在 DummyBackendQueue中,它实现了一个 no-op 的Backend。
在任何垃圾回收环境中,你可能会关注到吞吐量量(做无用功),延迟(响应),并驻留集大小(footprint)。
Go 的1.2版本,GC 采用,mark-and-sweep (parallel), non-generational, non-compacting, stop-the-world 和 mostly precise。这主要是因为剩余的工作未完成(它预定于Go 1.3 实现)。
Go 的 GC 一定会不断改进,但普遍的真理是:你创建的垃圾越少,收集的时间越少。
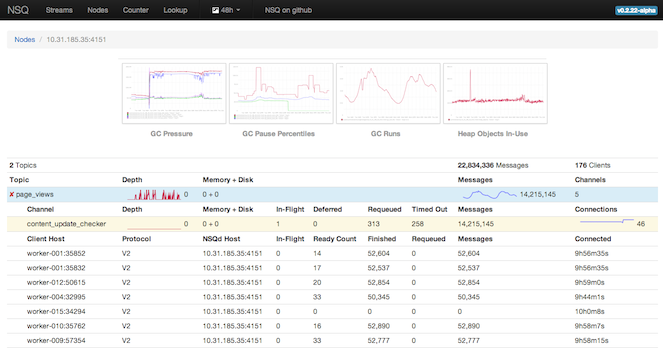
首先,重要的是要了解 GC 在真实的工作负载下是如何表现。为此,nsqd 以 statsd 格式发布的 GC 统计(伴随着其他的内部指标)。nsqadmin 显示这些度量的图表,让您洞察 GC 的影响,频率和持续时间:
为了切实减少垃圾,你需要知道它是如何生成的。再次 Go toolchain 提供了答案:
testing package 和 go test -benchmem 来 benchmark 热点代码路径。它分析每个迭代分配的内存数量(和 benchmark 运行可以用 benchcmp 进行比较)。
考虑到这一点,下面的优化证明对 nsqd 是有用的:
[]byte 到 string 的转换
sync.Pool 又名 issue 4720)
make 时指定容量)并且总是知道其中承载元素的数量和大小
interface{})或一些不必要的包装类型(例如一个多值的”go-chan” 结构体)
defer (它也消耗内存)
NSQ 的 TCP 协议 protocol_spec 是一个这些 GC 优化概念发挥了很大作用的的例子。
该协议用含有长度前缀的帧构造,使其可以直接高效的编码和解码:
[x][x][x][x][x][x][x][x][x][x][x][x]...
| (int32) || (int32) || (binary)
| 4-byte || 4-byte || N-byte
------------------------------------...
size frame ID data
由于提前知道了帧部件的确切类型与大小,我们避免了 encoding/binary 便利 Read() 和 Write() 包装(以及它们外部 interface 的查询与转换),而是直接调用相应的 binary.BigEndian 方法。
为了减少 socket 的 IO 系统调用,客户端 net.Conn 都用 bufio.Reader 和bufio.Writer 包装。Reader 暴露了ReadSlice() ,它会重复使用其内部缓冲区。这几乎消除了从 socket 读出数据的内存分配,大大降低 GC 的压力。这可能是因为与大多数命令关联的数据不会被忽视(在边缘情况下,这是不正确的,数据是显示复制的)。
在一个更低的水平,提供一个 MessageID 被声明为 [16]byte,以便能够把它作为一个 map key(slice 不能被用作 map key)。然而,由于从 socket 读取数据存储为 []byte,而不是通过分配字符串键产生垃圾,并避免从 slice 的副本拷贝的数组形式的MessageID, unsafe package 是用来直接把 slice 转换成一个 MessageID:
id := *(*nsq.MessageID)(unsafe.Pointer(&msgID))
注: 这是一个 hack。它将不是必要的,如果编译器优 和 Issue 3512 解决这个问题。另外值得一读通过issue 5376,其中谈到的“const like” byte 类型 与 string 类型可以互换使用,而不需要分配和复制。
同样,Go 标准库只提供了一个数字转换成 string 的方法。为了避免 string 分配,nsqd 使用一个自定义的10进制转换方法在 []byte 直接操作。
这些看似微观优化,但却包含了 TCP 协议中一些最热门的代码路径。总体而言,每秒上万消息的速度,对分配和开销的数目显著影响:
benchmark old ns/op new ns/op delta BenchmarkProtocolV2Data 3575 1963 -45.09% benchmark old ns/op new ns/op delta BenchmarkProtocolV2Sub256 57964 14568 -74.87% BenchmarkProtocolV2Sub512 58212 16193 -72.18% BenchmarkProtocolV2Sub1k 58549 19490 -66.71% BenchmarkProtocolV2Sub2k 63430 27840 -56.11% benchmark old allocs new allocs delta BenchmarkProtocolV2Sub256 56 39 -30.36% BenchmarkProtocolV2Sub512 56 39 -30.36% BenchmarkProtocolV2Sub1k 56 39 -30.36% BenchmarkProtocolV2Sub2k 58 42 -27.59%HTTP
NSQ 的 HTTP API 是建立在 Go 的 net/http 包之上。因为它只是 net/http,它可以利用没有特殊的客户端库的几乎所有现代编程环境。
它的简单性掩盖了它的能力,作为 Go 的 HTTP tool-chest 最有趣的方面之一是广泛的调试功能支持。该net/http/pprof 包直接集成了原生的 HTTP 服务器,暴露获取 CPU,堆,goroutine 和操作系统线程性能的 endpoints。这些可以直接从 go tool 找到:
$ go tool pprof http://127.0.0.1:4151/debug/pprof/profile
这对调试和分析一个运行的进程非常有价值!
此外,/stats endpoint 返回的指标以任何 JSON 或良好格式的文本来呈现,很容易使管理员能够实时从命令行监控:
$ watch -n 0.5 'curl -s http://127.0.0.1:4151/stats | grep -v connected'这产生的连续输出如下:
[page_views ] depth: 0 be-depth: 0 msgs: 105525994 e2e%: 6.6s, 6.2s, 6.2s
[page_view_counter ] depth: 0 be-depth: 0 inflt: 432 def: 0 re-q: 34684 timeout: 34038 msgs: 105525994 e2e%: 5.1s, 5.1s, 4.6s
[realtime_score ] depth: 1828 be-depth: 0 inflt: 1368 def: 0 re-q: 25188 timeout: 11336 msgs: 105525994 e2e%: 9.0s, 9.0s, 7.8s
[variants_writer ] depth: 0 be-depth: 0 inflt: 592 def: 0 re-q: 37068 timeout: 37068 msgs: 105525994 e2e%: 8.2s, 8.2s, 8.2s
[poll_requests ] depth: 0 be-depth: 0 msgs: 11485060 e2e%: 167.5ms, 167.5ms, 138.1ms
[social_data_collector ] depth: 0 be-depth: 0 inflt: 2 def: 3 re-q: 7568 timeout: 402 msgs: 11485060 e2e%: 186.6ms, 186.6ms, 138.1ms
[social_data ] depth: 0 be-depth: 0 msgs: 60145188 e2e%: 199.0s, 199.0s, 199.0s
[events_writer ] depth: 0 be-depth: 0 inflt: 226 def: 0 re-q: 32584 timeout: 30542 msgs: 60145188 e2e%: 6.7s, 6.7s, 6.7s
[social_delta_counter ] depth: 17328 be-depth: 7327 inflt: 179 def: 1 re-q: 155843 timeout: 11514 msgs: 60145188 e2e%: 234.1s, 234.1s, 231.8s
[time_on_site_ticks] depth: 0 be-depth: 0 msgs: 35717814 e2e%: 0.0ns, 0.0ns, 0.0ns
[tail821042#ephemeral ] depth: 0 be-depth: 0 inflt: 0 def: 0 re-q: 0 timeout: 0 msgs: 33909699 e2e%: 0.0ns, 0.0ns, 0.0ns
最后,每个 Go release 版本带来可观的 HTTP 性能提升autobench。与 Go 的最新版本重新编译时,它总是很高兴为您提供免费的性能提升!
对于其它生态系统,Go 依赖关系管理(或缺乏)的哲学需要一点时间去适应。
NSQ 从一个单一的巨大仓库衍化而来的,包含相关的 imports 和小到未分离的内部 packages,完全遵守构建和依赖管理的最佳实践。
有两大流派的思想:
GOPATH 环境变量包含这些固定依赖。
注: 这确实只适用于二进制包,因为它没有任何意义的一个导入的包,使中间的决定,如一种依赖使用的版本。
NSQ 使用 gpm 提供如上述2种的支持。
它的工作原理是在 Godeps 文件记录你的依赖,方便日后构建 GOPATH 环境。为了编译,它在环境里包装并执行的标准 Go toolchain。该 Godeps 文件仅仅是 JSON 格式,可以进行手工编辑。
Go 提供了编写测试和基准测试的内建支持,这使用 Go 很容易并发操作进行建模,这是微不足道的建立起来的一个完整的实例 nsqd 到您的测试环境中。
然而,最初实现有可能变成测试问题的一个方面:全局状态。最明显的 offender 是运行时使用该持有 nsqd 的引用实例的全局变量,例如包含配置元数据和到 parent nsqd 的引用。
某些测试会使用短形式的变量赋值,无意中在局部范围掩盖这个全局变量,即 nsqd := NewNSQd(...) 。这意味着,全局引用没有指向了当前正在运行的实例,破坏了测试实例。
要解决这个问题,一个包含配置元数据和到 parent nsqd 的引用上下文结构被传来传去。到全局状态的所有引用都替换为本地的语境,允许 children(话题(topic),通道(channel),协议处理程序等)来安全地访问这些数据,使之更可靠的测试。
一个面对不断变化的网络条件或突发事件不健壮的系统,不会是一个在分布式生产环境中表现良好的系统。
NSQ 设计和的方式是使系统能够容忍故障而表现出一致的,可预测的和令人吃惊的方式来实现。
总体理念是快速失败,把错误当作是致命的,并提供了一种方式来调试发生的任何问题。
但是,为了应对,你需要能够检测异常情况。
NSQ 的 TCP 协议是面向 push 的。在建立连接,握手,和订阅后,消费者被放置在一个为 0 的 RDY 状态。当消费者准备好接收消息,它更新的 RDY 状态到准备接收消息的数量。NSQ 客户端库不断在幕后管理,消息控制流的结果。
每隔一段时间,nsqd 将发送一个心跳线连接。客户端可以配置心跳之间的间隔,但 nsqd 会期待一个回应在它发送下一个心掉之前。
组合应用级别的心跳和 RDY 状态,避免头阻塞现象,也可能使心跳无用(即,如果消费者是在后面的处理消息流的接收缓冲区中,操作系统将被填满,堵心跳)
为了保证进度,所有的网络 IO 时间上限势必与配置的心跳间隔相关联。这意味着,你可以从字面上拔掉之间的网络连接 nsqd 和消费者,它会检测并正确处理错误。
当检测到一个致命错误,客户端连接被强制关闭。在传输中的消息会超时而重新排队等待传递到另一个消费者。最后,错误会被记录并累计到各种内部指标。
非常容易启动 goroutine。不幸的是,不是很容易以协调他们的清理工作。避免死锁也极具挑战性。大多数情况下这可以归结为一个顺序的问题,在上游 goroutine 发送消息到 go-chan 之前,另一个 goroutine 从 go-chan 上接收消息。
为什么要关心这些?这很显然,孤立的 goroutine 是内存泄漏。内存泄露在长期运行的守护进程中是相当糟糕的,尤其当期望的是你的进程能够稳定运行,但其它都失败了。
更复杂的是,一个典型的 nsqd 进程中有许多参与消息传递 goroutines。在内部,消息的“所有权”频繁变化。为了能够完全关闭,统计全部进程内的消息是非常重要的。
虽然目前还没有任何灵丹妙药,下列技术使它变得更轻松管理。
sync 包提供了 sync.WaitGroup, 可以被用来累计多少个 goroutine 是活跃的(并且意味着一直等待直到它们退出)。
为了减少典型样板,nsqd 使用以下装饰器:
type WaitGroupWrapper struct {
sync.WaitGroup
}
func (w *WaitGroupWrapper) Wrap(cb func()) {
w.Add(1)
go func() {
cb()
w.Done()
}()
}
// can be used as follows:
wg := WaitGroupWrapper{}
wg.Wrap(func() { n.idPump() })
...
wg.Wait()
有一个简单的方式在多个 child goroutine 中触发一个事件是提供一个 go-chane,当你准备好时关闭它。所有在那个 go-chan 上挂起的 go-chan 都将会被激活,而不是向每个 goroutine 中发送一个单独的信号。
func work() {
exitChan := make(chan int)
go task1(exitChan)
go task2(exitChan)
time.Sleep(5 * time.Second)
close(exitChan)
}
func task1(exitChan chan int) {
<-exitChan
log.Printf("task1 exiting")
}
func task2(exitChan chan int) {
<-exitChan
log.Printf("task2 exiting")
}
实现一个可靠的,无死锁的,所有传递中的消息的退出路径是相当困难的。一些提示:
理想的情况是负责发送到 go-chan 的 goroutine 中也应负责关闭它。
如果 message 不能丢失,确保相关的 go-chan 被清空(尤其是无缓冲的!),以保证发送者可以取得进展。
另外,如果消息是不重要的,发送给一个单一的 go-chan 应转换为一个 select 附加一个退出信号(如上所述),以保证取得进展。
一般的顺序应该是
WaitGroup 等待 goroutine 退出(如上文)
最后,日志是您所获得的记录 goroutine 进入和退出的重要工具!。这使得它相当容易识别造成死锁或泄漏的情况的罪魁祸首。
nsqd 日志行包括 goroutine 与他们的 siblings(and parent)的信息,如客户端的远程地址或话题(topic)/通道(channel)名。
该日志是详细的,但不是详细的日志是压倒性的。有一条细线,但 nsqd 倾向于发生故障时在日志中提供更多的信息,而不是试图减少繁琐的有效性为代价。
邮箱 626512443@qq.com
电话 18611320371(微信)
QQ群 235681453
Copyright © 2015-2024
备案号:京ICP备15003423号-3